
KI: betydningen for arbeidsstyrken. En analyse av potensialet for kunstig intelligens-drevet effektivisering i norsknæringsliv
Innovasjoner som ChatGPT har vist hvordan generativ kunstig intelligens (KI) kan effektivisere en lang rekke arbeidsoppgaver. Basert på oppgavebeskrivelser av 923 yrker, estimerer vi i denne studien effektiviseringspotensialet til store generative språkmodeller i Norge.
 Trygve Leithe SvalheimData Scientist, Menon
Economics
Trygve Leithe SvalheimData Scientist, Menon
Economics John Oskar Holmen SkjeldrumAnalyst, Menon
Economics
John Oskar Holmen SkjeldrumAnalyst, Menon
Economics Jonas ErraiaMenon Economics
Jonas ErraiaMenon Economics Kristoffer MidttømmePartner, Menon
Economics og Lecturer
på Universitet i Oslo
Kristoffer MidttømmePartner, Menon
Economics og Lecturer
på Universitet i Oslo Sebastian Winther-LarsenData Scientist, Menon
Economics • 2024, Utgave 6
Sebastian Winther-LarsenData Scientist, Menon
Economics • 2024, Utgave 6
For å estimere effektiviseringspotensialet benytter vi en videreutvikling av metoden til Eloundou, m.fl. (2023). Vi kombinerer unike beskrivelser av 923 yrker og tilhørende arbeidsoppgaver med data på yrkesfordelt sysselsetting i Norge. Vår analyse viser at selv med de mest konservative anslag kan rundt 56 prosent av arbeidstakere kutte arbeidstiden med minst 10 prosent, og en fjerdedel kan redusere den med minst 20 prosent ved bruk av KI. En regresjonsanalyse viser at effektiviseringspotensialet er positivt korrelert med både høyere lønn og høyere utdanning. Effekten ser dog ut til avta ved høye nivåer av begge variabler. Avslutningsvis estimerer vi at effektivisering for norsk økonomi, ved fullstendig KI-adopsjon, tilsvarer verdiskaping på 482 milliarder kroner, eller omtrent 14 prosent av Fastlands-Norges BNP i 2022. Studien diskuterer også hvordan effektiviseringen vil påvirke ledigheten i Norge. Det antas at en betydelig økning i den strukturelle arbeidsledighet er lite sannsynlig. Tidligere teknologiske fremskritt har skapt nye jobbmuligheter
og økt etterspørsel, og Norge opplever arbeidskraftsmangel i både offentlig og privat sektor.
1. INTRODUKSJON
Siden lanseringen av ChatGPT i november 2022, har store deler av samfunnet blitt stadig mer oppmerksom på det enorme potensialet til store språkmodeller og andre former for generativ kunstig intelligens (KI). Kun måneder etter lanseringen demonstrerte OpenAI store fremskritt med en ny versjon: GPT-4. Teknologien er under stadig utvikling, men tilgjengelige versjoner viser allerede evner som på sikt vil ha stor betydning for mange deler av samfunnet vårt, inkludert arbeidsmarkedet. Tidligere forskning gjort av OpenAI selv, har pekt på store gevinster ved bruk av ChatGPT og lignende verktøy i det amerikanske arbeidsmarkedet (Eloundou mfl., 2023). I dette analysenotatet utforsker vi, med en videreutvikling av OpenAIs metodikk, konsekvensene av KI-verktøy på det norske arbeidsmarkedet.
KI er et paraplybegrep som omfatter et enormt spekter av algoritmer, men et begrep som i 2024 i all hovedsak brukes til å omtale generative store språkmodeller. Det er også sånn vi bruker «KI» i denne studien. Store språkmodeller som GPT-4 er resultatet av avansert maskinlæring, hvor milliarder av parametere er finjustert gjennom trening på store mengder tekst og skiller seg fra enkle lineær-regresjonsalgoritmer på noen spesielt viktige områder. Store
språkmodeller er designet for å ta inn tekst og gjette på en ny mengde tekst basert på en matematisk likhet til teksten som ble matet inn. Ikke bare evner modellene å lese enorme mengder treningsdata, men de lar også brukeren interagere med dem gjennom naturlig språk. Disse evnene gjør dem fleksible og generaliserte og derfor anvendelig på et enormt spekter av problemer. Eksempler på slike arbeidsoppgaver strekker seg fra oversettelse, tekstbehandling, idé-sparring, kompleks problemløsing og kodeutvikling per i dag. For enkelhetens skyld vil vi med begrepet KI referere til disse store språkmodellene heretter.
Selv om språkmodeller har sine svakheter, spesielt når det gjelder generering av nøyaktig og faktabasert informasjon, utgjør den nyeste versjonen, GPT-4o, betydelig forbedring fra tidligere versjoner, som GPT-3. GPT-4o har evnen til å programmere enkle dataspill fra bunnen av med et minimum av menneskelig input, bestå den amerikanske advokateksamen med gode karakterer, og snakker hebraisk bedre enn forgjengeren snakket engelsk. Disse avanserte
funksjonene understreker det brede spekteret av anvendelser hvor språkmodeller kan komme til å spille en avgjørende rolle i fremtiden.
Vi bruker i denne artikkelen uttrykket «effektiviseringspotensial» om den mulige andelen av tiden knyttet til en arbeidsoppgave eller yrke som kan teoretisk sett kan gjennomføres av en KI-algoritme med tilfredsstillende kvalitet. Det er likevel viktig å merke seg at den faktiske effekten av å ta i bruk KI ikke er lik for alle. Man kan med fordel tenke på utfallet av KI-bruk som fallende på et spektrum.
På den ene enden av spekteret finner vi full-automatisering av eksisterende yrker, som representerer den mest dramatiske formen for endring. KI-teknologier har potensial til å erstatte menneskelig arbeidskraft i betydelig grad, spesielt i yrker hvor en stor andel av arbeidsoppgavene kan utføres av KI uten behov for menneskelig innsats. Denne omveltningen har vi sett eksempler på, som når nettavisen Gizmodo valgte å permittere sin spanske avdeling og erstatte dem med KI-drevne oversettelser (The Verge, 2023). For de som er utdannet innen yrker som står overfor full-automatisering, kan konsekvensene variere fra intern
omplassering og omskolering til ny karriereorientering eller til og med arbeidsledighet. I visse tilfeller, som for frilansere innen tekstproduksjon og oversetting, ser vi allerede redusert etterspørsel – for eksempel har antallet jobber i denne sektoren i USA falt med 2 prosent etter innføringen av ChatGPT (Hui, Reshef og Zhou, 2023). Historisk har lignende trender ført til at yrker, som telefonoperatør, har forsvunnet helt etter automatisering, da ny teknologi erstattet den menneskelige innsatsen fullstendig.
På den helt andre siden av spektret finner vi yrker der KI har liten eller ingen merkbar effekt. Dette gjelder spesielt i yrker dominert av fysisk arbeid eller der menneskelig interaksjon spiller en sentral rolle. Slike yrker inkluderer helsepersonell som sykepleiere og terapeuter, der den emosjonelle tilknytningen og pasientomsorgen står sentralt. På samme måte gjelder dette for vanlige praktiske yrker som snekker, rørlegger eller murer som sannsynligvis vil påvirkes minimalt av språkmodeller.For de aller fleste yrker vil effektiviseringspotensialet imidlertid falle mellom disse ytterpolene. I denne mellomposisjonen
på påvirkningsspektret fører ikke KI nødvendigvis til erstatning av arbeidskraft, men snarere til en forbedring av produktiviteten og effektiviteten i eksisterende yrker. Dette kan manifestere seg på ulike måter, fra å gjøre det mulig for arbeidstakere å fullføre de samme oppgavene med færre ressurser, til å utføre nye oppgaver som tidligere krevde høyere faglig kompetanse. Dette sistnevnte fenomenet, ofte kalt «forsterkningseffekten» kan for eksempel
oppstå når en sykepleier kan utføre diagnostiserings-oppgaver tidligere forbeholdt leger, uten at behovet for leger forsvinner, eller ved at kompetansegapet innad i samme yrke reduseres.
Gitt denne brede paletten av mulige utfall, er det viktig å forstå de økonomiske, sosiale, og politiske implikasjonene av KI i arbeidsmarkedet. På samme måte som arbeiderbevegelsen sørget for bedre arbeidsvilkår i kjølvannet av den industrielle revolusjonen, tilbyr KI-revolusjonen en unik mulighet for å revurdere og kanskje omstrukturere arbeidsuken videre.
2.LITTERATURENS VURDERING AV KUNSTIG INTELLIGENS PÅ ARBEIDSMARKEDET
Det store spennet i effektiviseringspotensial på tvers av yrker gjør det vanskelig å vurdere hva den samlede effekten av KI-drevet effektivisering blir på både arbeidsmarkedet og økonomien. Det er imidlertid utført en del forskning på emnet, og under går vi kort gjennom noen av de viktigste bidragene til feltet. Etter seks måneder med tilgang til avanserte språkmodeller har arbeidsledighetsraten globalt sett forblitt stabil, noe en nylig OECD-studie bekrefter (OECD, 2023). Studien finner ingen signifikant nedgang i etterspørselen etter menneskelig arbeidskraft. En sannsynlig årsak er at vi fortsatt er i en tidlig fase av teknologisk adopsjon, hvor det tar tid å identifisere de mest effektive bruksområdene. I tillegg indikerer studien at bedrifter kan være tilbakeholdne med å permittere og avskjedige ansatte, og heller lar arbeidsstyrken reduseres naturlig gjennom pensjonering og frivillige oppsigelser. Denne observerte stabiliteten i arbeidsmarkedet samsvarer godt med Everett Rogers’ teori «Diffusion of Innovations» (Rogers, 2003) som forklarer at ny teknologi adopteres i etapper, der en liten gruppe innovatører går foran. Resten av markedet venter ofte på å se deres suksess før de følger etter. Følgelig kan vi forvente at de mest markante
endringene vil komme til syne etter hvert som teknologien modner og blir mer allment akseptert.
Samtidig indikerer flere og flere studier at store språkmodeller fører til positiv gevinst i arbeidsmarkedet. For eksempel viste en studie av Erik Brynjolfsson mfl. (2023) at tilgang til en KI-basert samtaleassistent økte produktiviteten med 14 prosent i gjennomsnitt blant kundeservicearbeidere. Nybegynnere og lavt kvalifiserte arbeidere så en forbedring på 35 prosent i produktiviteten, noe som underbygger argumentet for at KI kan være en katalysator for økt
effektivitet, særlig blant mindre erfarne arbeidere. En studie av Fabrizio Dell’Acqua mfl. (2023), utført på Boston Consulting Group støtter dette med å vise at konsulenter fullførte 12 prosent flere arbeidsoppgaver, 25 prosent raskere og med 40 prosent bedre kvalitet sammenlignet med en kontrollgruppe innenfor en gitt tidsramme. Det var igjen de lavest kvalifiserte arbeiderne som så den høyeste forbedring i produktivitet og kvalitet på 43 prosent. Studien pekte også på viktigheten av å kjenne kapasitetene til KI oppgaver hvor KI har begrensede evner, hadde konsulenter 19 prosent lavere sannsynlighet for å uføre oppgaver riktig med hjelp fra KI sammenlignet med dem uten hjelp.
En annen studie av Shakked Noy og Whitney Zhang (2023) fant at assisterende chatboter som ChatGPT kunne øke produktiviteten i skriveoppgaver betydelig, redusere tidsbruken med 40 prosent og forbedre output-kvaliteten med 18 prosent. Dette demonstrerer at selv i komplekse, kreative oppgaver kan KI ha en markant positiv effekt.
Siden vår opprinnelige studie ble publisert som et forskningsnotat våren 2023, har også Samfunnsøkonomisk analyse (SØA) publisert en lignende rapport med navn «Kunstig intelligens i Norge – Nytte, muligheter og Barrierer». I kontrast til vår, har de ikke beregnet estimater på effektiviseringspotensial, men heller utført en metastudie basert McKinsey artiklene «The economic potential of generative AI: The next productivity frontier» (2023) og «Det økonomiske potensialet til GenAI i Norge. Det neste fremskrittet innen produktivitet» (2023) samt Eloundou mfl. (2023) og Briggs og Kodani (2023). Samtlige av disse studiene benytter metoder som er beslektet med vår og baserer seg på kategorisering av arbeidsoppgaver. SØA analyserer fire separate scenarioer, der gevinstene kan slå ut som enten redusert sysselsetting eller økt produktivitet. I scenarioet hvor gevinsten deles likt finner de en økning på i årlig verdiskaping på ca. 250 milliarder ved full utnyttelse av KI (2040 resultater i 2022 kroner). I kontrast anslår vi en total årlig verdiskaping på 500 milliarder, men dette under antagelsen om at all gevinst tas ut i verdiskaping. Det er derfor rimelig å anta at estimatene er relativt like i SØAs scenario «C», hvor verdiskapingsgevinsten dobles (se figur 3.3 og 3.4 i SØAs rapport), og at dersom vi valgte å spre gevinstene mellom redusert sysselsetting eller økt produktivitet ville resultatene vært tilnærmet like.
I slutningen av denne analysen gir vi en kort vurdering av effektene av automatisering på samfunnsøkonomien og arbeidsmarkedet i Norge. Vår målsetting er å gi en helhetlig og nyansert forståelse av hvordan KI kan forme det norske arbeidsmarkedet, med fokus på de økonomiske, sosiale og politiske utfordringene, og mulighetene, som ligger foran oss.
3.METODIKK OG DATA
Formålet er å vurdere effektiviseringspotensialet til ulike yrker som følge av KI, hvor vi definerer effektiviseringspotensial til å være graden av tidsbesparelse for ulike arbeidsoppgaver i et yrke. Data på disse er hentet i den amerikanske ONET-databasen, som inneholder en liste med over 923 yrker og tilhørende arbeidsoppgaver. Hver yrkesgruppe i databasen har i gjennomsnitt 20 forskjellige arbeidsoppgaver beskrevet. ONET-databasen kategoriserer arbeidsoppgaver for hvert yrke som enten kjerneoppgaver («core tasks») eller supplerende oppgaver («supplement tasks»). Kjerneoppgaver defineres som oppgaver som er essensielle for et yrke, basert på høy relevans og viktighetsvurderinger. Et eksempel på en kjerneoppgave for en regnskapsfører kan være «Utarbeide, gjennomgå eller analysere regnskapsbøker, finansregnskaper eller andre økonomiske rapporter for å vurdere nøyaktighet, fullstendighet og samsvar med rapporterings- og prosedyrestandarder.», mens en supplementær oppgave kan være «Utarbeide skjemaer og manualer for regnskaps- og bokføringspersonell og veilede deres arbeidsaktiviteter.» Kjerneoppgavene utgjør i gjennomsnitt omkring 70 prosent av alle samlede oppgavene i databasen, men andelen varierer noe mellom hvert yrke.
Siden yrkeskodene i ONET-databasen ikke tilsvarer SSBs yrker, benytter vi et kryssreferansedatasett fra US Bureau of Labor Statistics for å konvertere de ulike yrkeskodene til ISCO. For å videre vurdere effekten på arbeidsstyrken har vi koblet data fra den amerikanske ONET databasen med
detaljert data fra Statistisk sentralbyrå (SSB). Vi ha har brukt følgende datatabeller fra SSB.
- 08536: Kjønn- og næringsfordeling (88 grupper) blant sysselsatte (15-74 år). 4. kvartal (K) 2008 –
2022: Denne tabellen beskriver sysselsettingen for bosatte i Norge på et detaljert nivå. Dataene er brukt til å undersøke effektiviseringspotensialet på næring- og fylkesnivå. Næringskategoriseringen er basert på SN2007.
- Sysselsatte 15-74 år, etter arbeidsstedsfylke. Person og prosent. 4. kvartal: Denne tabellen beskriver sysselsettingen
for bosatte i Norge på et detaljert og regionalt nivå. - 09391: Hovedtall fylkesfordelt nasjonalregnskap,etter region, statistikkvariabel og år: Denne tabellen viser det fylkesfordelte nasjonalregnskapet.
- Spesialbestilling fra SSB: Denne tabellen inneholder mer finmasket data på sysselsatte i Norge enn vanlig tabeller SSB leverer. Her finner vi antall sysselsatte innenfor ett spesifikt yrke for alle næringene. Tabellen inneholder også en ISCO-08-Kode, som er brukt til å knytte tabellen til vår data på effektiviseringspotensialet
i prosent.
For å kunne beregne yrkesfordelt eksponering for KI, har vi brutt ned yrker i sine enkelte arbeidsoppgaver klassifisert hver arbeidsoppgave etter dennes eksponering for KI-verktøy. Vi deler kategoriserer arbeidsoppgaver i fire grupper: minimal effekt (ME), god effekt (GE), effekt med ekstraverktøy (EE) og effekt med synsevner (ES). De to siste grupper dekker over arbeidsoppgaven som kan effektiviseres dersom språkmodellen har et ekstra økosystem
bygget rundt seg, eller evnen til å se bilde eller film. Metodikken for å kategorisere de arbeidsoppgavene i de fire kategoriene er beskrevet i et detaljert instruksjonsark (Se vedlegg 1).
For å øke nøyaktigheten i vår analyse, har vi sammenlignet resultatene av GPT-4s kategorisering med et mindre utvalg av manuelt kategoriserte oppgaver. Dette er gjort for å illustrere potensielle forskjeller mellom KI- og menneskelig vurderinger, samt kvalitetssikre den brukte metodikken. I tillegg er resultatene løpende blitt evaluert gjennom analyseprosessen for å avdekke eventuelle inkonsekvenser.
Metodikken er som beskrevet inspirert av Eloundou mfl. (2023), som også estimerte et lignende potensial for den amerikanske arbeidsstyrken. Det er viktig å påpeke at denne studien ikke er fagfellevurdert og er utført av forskere ansatt i OpenAI, som er firmaet bak språkmodellen GPT-4 som brukes i både vår og deres analyse. Det betyr at forfatterne potensielt kan ha økonomisk insentiv for å omtale modellens egenskaper positivt. Vi bruker imidlertid ingen av forfatternes resultater, men bare metodikk og er på så måte ikke avhengig av deres beskrivelse eller presentasjon av resultater. I den grad det kan være bias, er det ikke knyttet til at GPT-4 i for høy grad vurderer KI-modellers evner til å automatisere evner. Dette er ikke utenkelig, men det er vanskelig å se for seg at dette kan knyttes direkte til forfatternes økonomiske situasjon. Vi har likevel valgt å redusere potensielt positivt bias ved å gjennomføre en rekke uavhengige kategoriseringer av alle arbeidsoppgaver og velge det mest konservative resultatet fremfor å beregne et gjennomsnitt. Denne fremgangsmåten i kombinasjon med menneskelig validitetskontroller av en betydelig delmengde av arbeidsoppgavene bidrar til å redusere et eventuelt implisitt bias i GPT-4s vurderinger.
To metriske indikatorer, a og ß , brukes deretter for å kvantifisere en samlet score per yrke. Først beregnes a som en vektet andel av oppgaver kategorisert som «God effekt», der kjerneoppgaver (som kategorisert i O*NET-databasen)vektes dobbelt. ß er en utvidelse av a og inkluderer også «effekt med ekstraverktøy» og «effekt med synsevner», men kun med 50 prosents vekt hver. Formlene er som følger,


Det endelige resultatet er et datasett med 923 yrkesrader, hver med en score beregnet ved hjelp av a – eller ß -indikatorene.
En nøkkelforskjell mellom vår metode og den benyttet av OpenAI’s artikkel, er knyttet til kategoriseringen av hver enkelt arbeidsoppgave. I motsetning til OpenAI, gjennomfører vi analysen fem ganger for hver arbeidsoppgave. Som konsekvens av modellens innebygde stokastiske natur gir identiske input ikke alltid nøyaktig samme output. Vår konservative strategi innebærer at vi systematisk velger det mest pessimistiske av de fem svarene. Dette minimerer risikoen for at vi overestimerer andelen av arbeidsoppgavene som kan effektiviseres i et gitt yrke. En sammenligning mellom vår konservative metode og den benyttet av OpenAI er visualisert i Figur 1.
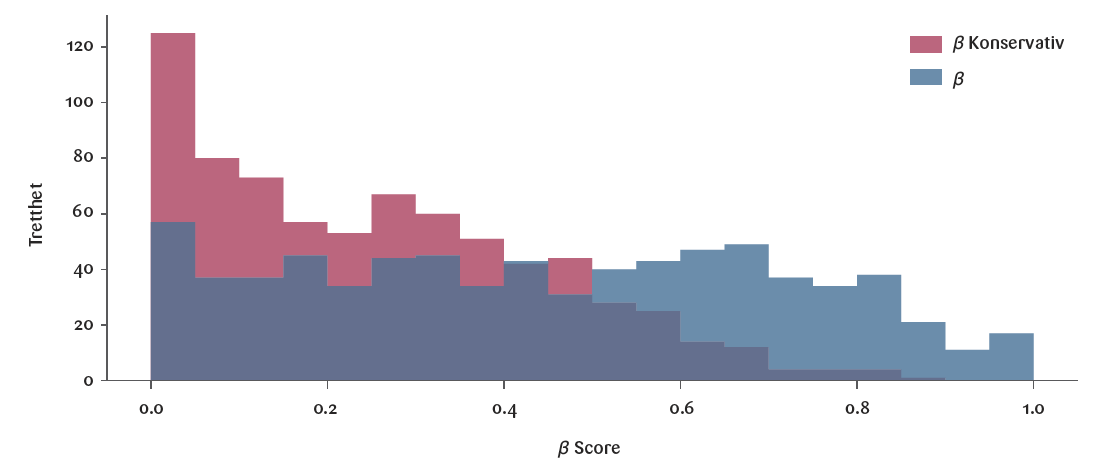
tilnærminger.
4.RESULTATER
For å undersøke påvirkningen på det norske arbeidsmarkedet kobler vi våre estimerte effektiviseringspotensial for hvert yrke på sysselsettingstabeller fra SSB. For å bestemme effektiviseringspotensialet i de ulike næringene (EN), gjør vi følgende
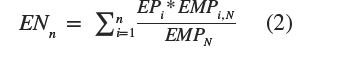
Der EP i er effektiviseringspotensialet for yrke i, mens EMP i, N er sysselsetting i yrke i næring N og EMP N er samlet sysselsetting i næring N.
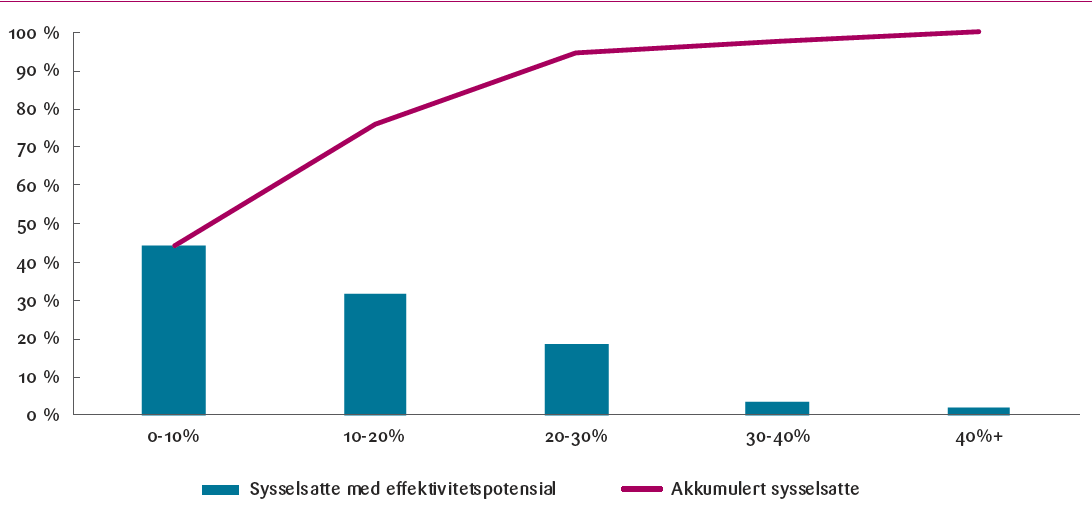
Overordnede resultater viser at en gjennomsnittlig arbeidstaker i Norge kan effektivisere 12 prosent av sin arbeidstid ved hjelp av KI-verktøy. I figur 2 under, viser vi en fordeling av andelen av sysselsetting som havner innenfor de ulike anslagene for effektivitetspotensial.
Som vi ser av figuren, har 44 prosent av arbeidsstyrken et effektivitetspotensial på mellom 0 og 10 prosent. Dette innebærer at over halvparten av arbeidsstyrken har en mulig effektiviseringsgevinst på over 10 prosent. Videre viser dataene at omkring 30 prosent av de sysselsatte har et potensial for effektivisering på mellom 10 og 20 prosent, noe som betyr at 25 prosent av arbeidsstyrken mulig kan oppnå en økt effektivisering på minst 20 prosent.
For de mest eksponerte yrkesgruppene, som utgjør omtrent 2 prosent av arbeidsstyrken, kan effektivitetspotensialet overstige 40 prosent. 2 prosent tilsvarer om lag 25 000 personer.
4.1. Effektivitetspotensial innen ulike yrker og næringer
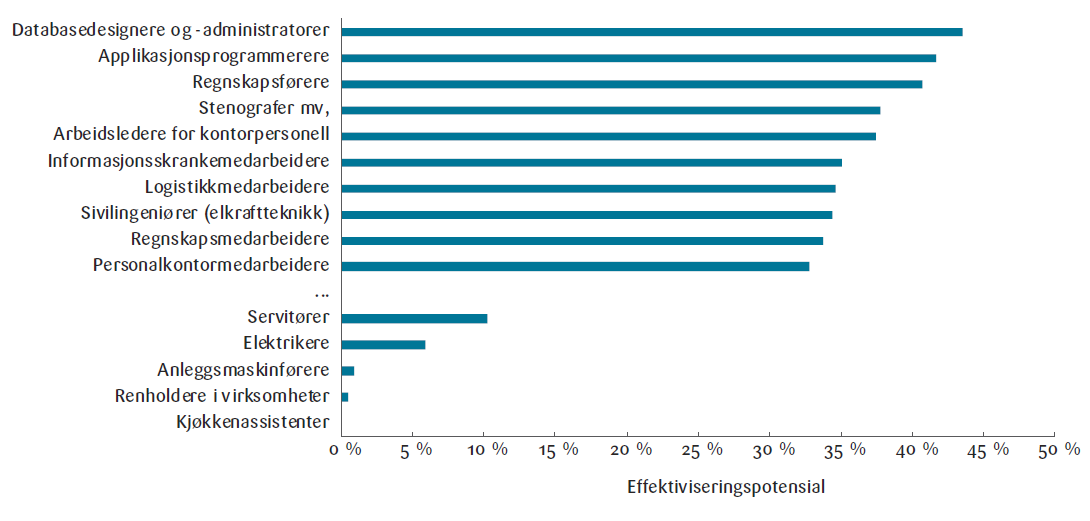
Figur 3 viser effektivitetspotensialet for 15 yrker, hvor de 10 øverste har det høyeste potensial for effektivisering. Blant disse er applikasjonsprogrammerere, regnskapsførere og databasedesignere. Disse yrkene er preget av arbeidsoppgaver som primært involverer databehandling, noe som utgjør en ideell arena for store språkmodeller og KI-verktøy, som har vist seg svært effektive på slike områder. Alle disse yrkene har et effektiviseringspotensial på
over 33 prosent.
Videre ser vi at KI kan effektivisere yrker innen ledelse og organisasjon betydelig. Dette er en konsekvens av at
KI-verktøy klarer å planlegge, analysere og strukturere store mengder informasjon.
Nederst på figur 3 finner vi yrkene servitører, elektrikere, anleggsmaskinførere, renholdere og kjøkkenassistenter. Dette er ikke de fem yrkene med den laveste effektiviseringen, men representerer et utvalg kjente yrker med lavt potensial for effektivisering gjennom KI. Typisk for disse yrkene er at de ofte krever en del manuelle arbeidsoppgaver, fleksibilitet og tilpasningsevne i uforutsigbare miljøer. Dette gjør det utfordrende for KI å utføre oppgavene.
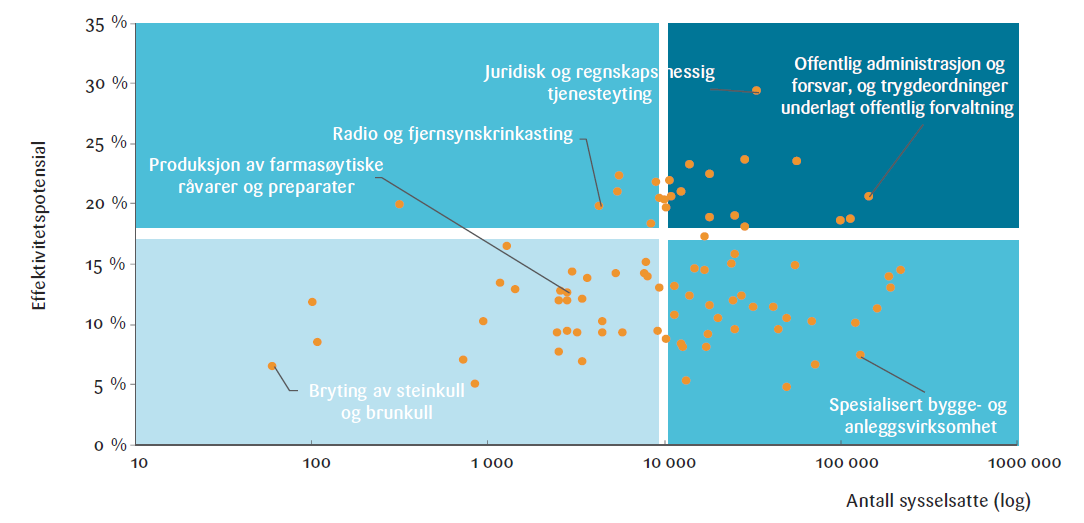
Fordelingen av effektiviseringspotensialet blant ulike yrker gjenspeiles naturligvis i hvilke næringer som samlet sett har størst potensial for effektivisering. Ved å kombinere ykresspesefikke data med antall ansatte i hver næring, har vi beregnet dette potensialet. Dette er illustrert i figur 4 under. Overordnet ser vi mye variasjonen mellom de ulike næringene. Boksen øverst til høyre i figuren, ser vi næringer med både et høyt effektivitetspotensial og et stort antall sysselsatte, som juridisk og regnskapsmessig, finansieringsvirksomhet og offentlig administrasjon. Dette er næringer som kan se en stor effektiviseringsgevinst ved å innføre KI i sine arbeidsoppgaver. Disse er stort sett preget av rutinepregede og standardiserte oppgaver, som dokumenthåndtering,
kontraktutarbeidelse og regnskapsførsel, hvor KI har vist særlig sterke egenskaper. Den store andelen sysselsatte i disse yrkene betyr at KI kan få en bred effekt i disse sektorene og gi store samfunnseffekter, både i form av produktivitet og økonomiske gevinster.
næringer.
Nederst til høyre finner vi næringer med mange sysselsatte, men et lavt effektivitetspotensial, som spesialisert bygge- og anleggsvirksomhet, serveringsvirksomhet og ulike omsorgstjenester. Disse næringene er preget av arbeidsoppgaver som krever høy grad av fysisk tilstedeværelse,
manuell dyktighet og tilpasning til uforutsigbare arbeidsmiljøer – faktorer som gir dem mindre potensial for effektivisering. Dermed vil KI sannsynligvis ha en begrenset direkte innflytelse på disse yrkene, men grunnet en stor arbeidsstyrke, kan man forvente noen mulige samfunnseffekter.
Videre finner vi øverst til venstre eksempler på næringer med høyt effektivitetspotensial, men få sysselsatte. Dette inkluderer informasjonstjenester og radio- og fjernsynskringkasting. Disse sektorene har en arbeidsstruktur der KI kan automatisere mange av oppgavene knyttet til innholdsproduksjon, datahåndtering og distribusjon på bedriftsnivå, men på grunn av næringens mindre arbeidsstyrke, vil den totale samfunnsmessige effekten være begrenset. Det er interessant at dette er den kvadrant med klart færrest næringer. Med andre ord er det få næringer med betydelig effektiviseringspotensial og få sysselsatte.
Boksen nederst til venstre finner vi næringer med både lavt effektivitetspotensial og få ansatte, som for eksempel gruvedrift, skogbruk og luftfart.. Næringer i
denne boksen reflekterer både at arbeidsoppgavene er vanskelige å automatisere, og at sektoren i seg selv sysselsetter relativt få personer. I slike tilfeller vil KI sannsynligvis ikke ha noen vesentlig innflytelse på produktiviteten, og vi vil ha små til ingen samfunnseffekter.
Basert på effektiviseringspotensial i hver næring og yrke kan vi også beregne den samfunnsøkonomiske nytteverdien (her vurderer vi ikke kostnadssiden) dersom man tar ut hele potensialet i økt produksjon. Dette må ses som en illustrativ øvelse, og gjøres under antakelse at fordelingen av arbeidsoppgavene ikke endrer seg og at det ikke kommer til nye oppgaver og yrker i forbindelse med at KI-modeller tas i bruk i hele samfunnet. Dette er selvsagt usannsynlig og vil tendere til å undervurdere den samfunnsøkonomiske nytteverdien. Vi beregner dette ved å kombinere effektiviseringspotensialet på næringer med nærings- og fylkesfordeltverdiskaping.
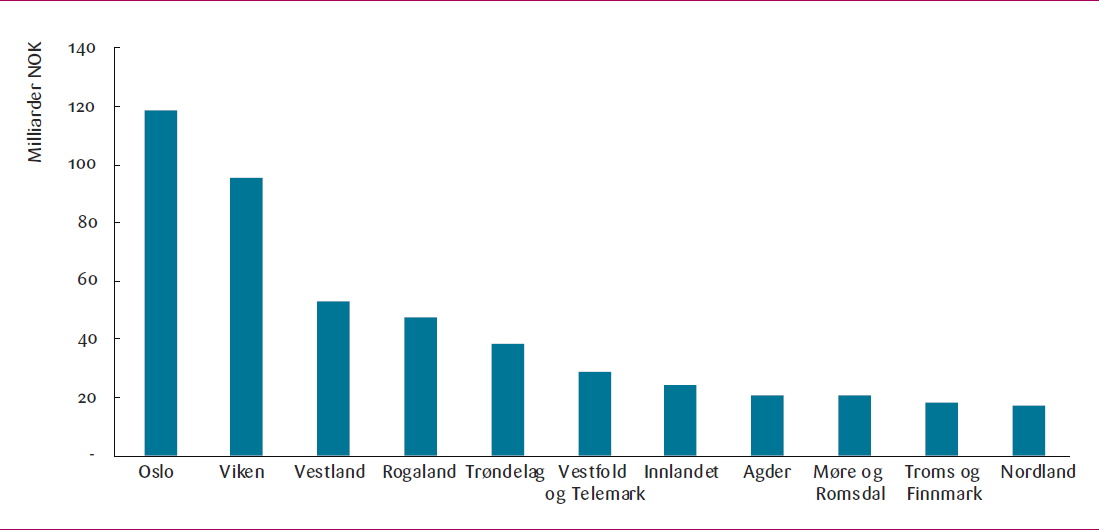
Samlet estimerer vi dette til et beløp mellom opp mot 482 milliarder kroner. Dette tilsvarer om lag 14 prosent av Fastland-Norges BNP. Det er viktig å være nøye med tolkningen av dette tallet. Det er verdien av de samlede arbeidsoppgavene som vi estimerer at KI kan automatisere i norsk
økonomi. Det er naturlig nok stor usikkerhet knyttet til dette tallet.
Vi har dessuten fordelt dette på fylker. Estimatene viser at verdiskapingspotensialet i Oslo er høyest med opptil 118 milliarder kroner årlig. Viken og Vestland har tilsvarende muligheter for verdiskaping, med henholdsvis 95 og 53 milliarder kroner i året. Selv i de nordligste fylkene, Nordland, samt Troms og Finnmark, som har de laveste absolutte potensialet, tilsvarer effektiviseringspotensialet verdiskaping på rundt 18 milliarder kroner. Det er her verdt å notere seg at disse resultatene er beregnet med det mest konservative estimatet for effektiviseringspotensialet.
4.2. Drivere for effektiviseringspotensial
Historisk har teknologi lagt grunnlaget for automatisering og industrialisering av manuelle arbeidsoppgaver, som i stedet blir utført av maskiner. Dette har hatt stor betydning for de relative produktivitets- og lønnsnivåer i ulike yrker. Mer spesifikt har tidligere bølger med automatisering ført
til at en større andel av nasjonal verdiskaping i mange land i dag går til kapitaleiere. I tillegg har fallet i etterspørsel etter manuelle og relativt lavt betalte jobber, ført til en økning i ulikheten i lønnsnivåer. (Acemoglu og Restrepo, 2018, 2021)
Som allerede beskrevet, skiller moderne KI seg fra tidligere automatiseringsbølger ved å kunne utføre og automatisere oppgaver som verken er manuelle eller fysiske. Siden brorparten av høyt betale yrker er ikke-fysiske indikerer dette at effektivitetspotensialet er høyeste i yrker med høye
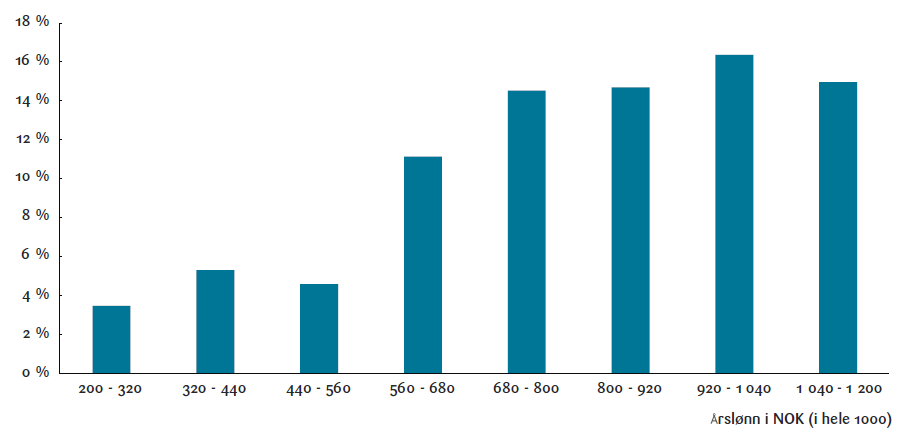
lønninger. Dette går frem av figur 6 som viser den gjennomsnittlig yrkesmessige effektiviseringspotensial for ulike lønnsintervaller. Effektiviseringspotensialet er beregnet som et sysselsettingsvektet gjennomsnitt for hvert lønnsintervall.
Selv om det er betydelig variasjon i effektivitetspotensialet innenfor hver lønnsgruppe, ser vi en overordnet tendens til at høyere lønn er forbundet med høyere effektivitetspotensial, som dog avtaker noe ved en årslønn over 800 000 kroner. Gjennomsnittlig effektivitetspotensial ligger på omkring 5 prosent for lønnsgrupper under 560 000 kroner, men dette tallet tredobles for grupper som tjener over 680 000 kroner. Vi ser et spesielt stort hopp for inntektsgruppene
over 560 000 kroner.
Siden det er positiv korrelasjon mellom lønn og utdanning er det interessant å analysere hvilken av disse som er positivt korrelert med effektiviseringspotensialet. For å undersøke dette i mer detalj gjennomfører vi en enkelt regresjonsanalyse.
Analysen ser på sammenhengen mellom effektiviseringspotensial, årslønn og utdanningsnivå. Utdanningsnivået i hvert yrke er representert ved en av fire kategorier: grunnskole, videregående skole, høyere utdanning (1–4 år på universitet eller høyskole) og høyere utdanning (+4 år på universitet eller høyskole) basert på flertallet av de sysselsatte i yrket. Ligningen vi ønsker å estimere ser ut som følger:
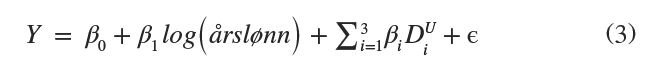
Der DiU er en dummy variabel for de ulike utdanningsnivåene, der den høyeste kategorien utgjør referansen og dermed ikke inkluderes som dummy. Det betyr at koeffisientene for de andre variablene må tolkes relativt til denne referansekategorien. Resultatene fra analysen er vist i Tabell 1 under.
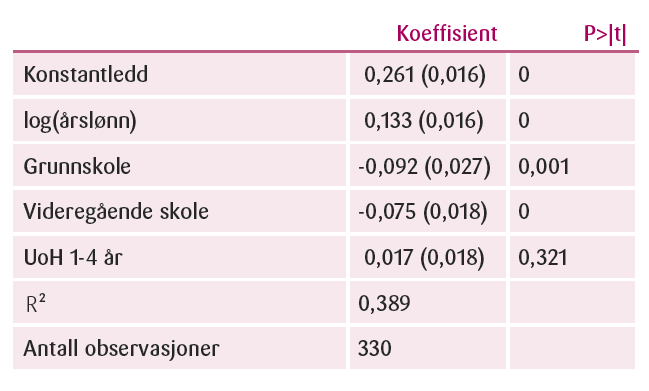
Det overordnede funnet er at både lønn og utdannelse er positivt korrelert med effektiviseringspotensial. En oppgang i lønn på 1 prosent er forbundet med en oppgang i effektiviseringspotensialet på 0,133 prosentpoeng.
Når det gjelder utdanningsnivå, viser analysen at grunnskole og videregående skole har signifikant negative koeffisienter på henholdsvis omkring -0,09 og -0,075, noe som indikerer at lavere utdanning er knyttet til lavere effektivitetspotensial. Imidlertid finner vi ingen signifikant koeffisient for UoH 1-4 år-variablen. Det betyr at modellen ikke tilsier en statistisk forskjell i effektivitetspotensialet mellom personer med kort og middelslang UoH-utdanning på den ene siden og de med master-grad eller doktorgrad på den andre. Dette speiler funnene i figur 6, der vi finner at effekten av lønn på effektiviseringspotensial avtar på høye
nivåer.
5. 4. DISKUSJON
Gitt det betydelige potensial identifisert over, er det grunn til at KI vil ha en betydelig innvirkning på det norske arbeidsmarkedet i årene som kommer. Historisk sett har teknologiske fremskritt kun ført til arbeidsledighet i små lommer, men som i gjennomsnitt ikke har stor effekt på arbeidsledighet. Ser vi tilbake til den industrielle revolusjonen på 1800-tallet, da mekanisering og automatisering begynte å transformere produksjonsprosesser, var det
bekymring for at håndverkere og tekstilarbeidere ville miste jobbene sine.
KI kan derimot argumenteres for å være en helt ny og annen type teknologi, som våre resultater har vist at til større grad treffer yrker med høyere årslønner og krav til utdanning, med kompliserte og regelbaserte oppgaver i form av databehandling, planlegging, analyse og strukturering. Det viktige skillet blir dermed om de eksponerte yrkene vil komplimenteres eller erstattes av KI. Vil den menneskelige arbeidskraften bli foreldet, på samme måte som historiens gamle teknologi har blitt erstattet med ny teknologi? Det er vanskelig å si noe konkret enda, men litteraturen har undersøkt yrkesgrupper som vil «komplementeres» og «erstattes» av KI. Briggs og Kodnani (2023) finner at 63 prosent av amerikanske jobber vil bli komplementert av KI, mens kun 7 prosent vil kunne erstattes. I Norge estimerer Implement at 5 prosent av norske arbeidstakere kan erstattes, med administrative oppgaver som de mest utsatte. Våre resultater støtter også dette funnet, med en overvekt av yrker bestående av administrative oppgaver som regnskapsførere,
arbeidsledere og kontormedarbeidere med størst effektivitetspotensial.
Undersøkelser fra Hui, Reshef og Zhou (2023) finner også allerede at antall frilansjobber i oversettelsessektoren allerede har falt med 2 prosent etter innføringen av ChatGPT. Dette funnet kan være et tegn på en fremtidig fall av etterspørsel, spesielt etter yrker knyttet til kunnskapsproduksjon.
Frilansernes tidligere evner og arbeidshistorikk modererte heller ikke disse effektene, som tilsier at de beste frilansere er uforholdsmessig påvirket av KI. I slike yrkesgrupper kan man forvente en omstilling til nye oppgavetyper eller yrker med lignende kompetanseprofil. Som nevnt studien til Dell’Acqua mfl. (2023) at konsulenter fullførte 12 prosent flere arbeidsoppgaver, 25 prosent raskere og med 40 prosent bedre kvalitet sammenlignet med en kontrollgruppe innenfor en gitt tidsramme. Det var igjen de lavest kvalifiserte arbeiderne som så den høyeste forbedring i produktivitet og kvalitet på 43 prosent.
Utviklingen i arbeidsmarkedet vil kunne ha stor effekt på utvikling i lønnsstruktur og utdanning. Ifølge Agrawal mfl. (2023) vil dette manifestere seg på ulike måter basert på hvordan yrkene komplementeres eller erstattes. KI-verktøy kan forbedre kapasiteten til arbeidstakere, spesielt de med lavere kvalifikasjoner, ved å gjøre det enklere å utføre komplekse oppgaver og bidra til økt inntjening. Hvis KI-verktøyene komplementere de ansatte, vil det resultere i produktivitetsvekst uten at arbeidsplasser nødvendigvis forsvinner. Med økt produktivitetsvekt i yrker hvor KI i større grad komplimenterer arbeidet, kan man også forvente økte lønnsinntekter til de ansatte. Denne effekten belyses også av Accenture (2023) som viser til at Vodafone allerede har begynt å omskolere sine kundeserviceansatte til jobber innenfor teknisk støtte eller digital markedsføring. På denne måten kan KI-verktøy hjelpe ansatte i kundeservice med å håndtere kompliserte spørsmål raskere og heller utføre andre, etterspurte arbeidsoppgaver.
Samtidig vil KI kunne skape etterspørsel etter nye typer tjenester og ekspertise vi ikke kan forutsi i dag. Historisk sett har teknologiske nyvinninger og automatisering ikke ført til permanent arbeidsledighet, men snarere økt lønninger og velstand, noe som igjen skapte nye jobber. Autor mfl. (2022) eksemplifiserer dette med hvordan 60 prosent av jobbene som finnes i USA i dag, ikke fantes i 1940. Dette er også bidrag som kan skape ytterlige verdiskaping enn det vi har kunnet estimere basert på dagens yrker og næringer.
Hvis KI til større grad erstatter arbeidsplasser enn å komplementere dem, vil det fortsatt sannsynligvis ikke føre til stor arbeidsledighet, men heller en omstrukturering av yrker. Finansdepartementet estimerer i Perspektivmeldingen at om man skal kunne dekke etterspørselen etter helse- og
omsorgstjenester i takt med at befolkningen blir eldre, trengs en vekst på 5 000 ansatte hvert år frem mot 2060, mer enn det dobbelte av veksten i sysselsettingen totalt. En mulig effekt kan dermed bli en omstrukturering av arbeid vekk fra dem som er mest eksponert for KI, til de tjeneste
som fortsatt trenger menneskelig interaksjon.
Det er vanskelig å konkludere med noe sikkert om hvordan teknologien vil påvirke arbeidsledigheten, men det er en risiko for at den vil kunne skape konsentrert arbeidsledighet i spesifikke yrker, næringer eller regioner. Alt i alt bør de færreste bør frykte for å miste jobben, som Teknologirådet
(2024) skriver i sin rapport om KI, blir det «mer sannsynlig å miste jobben til noen som bruker KI godt enn til KI i seg selv». Det er derfor viktig at man fokuserer på å utvikle KI-kompetansen og omstillingsevnen på norske arbeidsplasser.
6.REFERANSER
Accenture (2023) Work, workforce, workers Reinvented in the age of agenerative AI.
Acemoglu, D. og Restrepo, P. (2018) ‘The Race between Man and Machine: Implications of Technology for Growth, Factor Shares,
and Employment’, American Economic Review. Tilgjengelig fra: https://doi.org/10.1257/AER.20160696.
Acemoglu, D. og Restrepo, P. (2021) ‘Tasks, Automation, and the Rise in US Wage Inequality’, SSRN Electronic Journal. Tilgjengelig fra:
https://doi.org/10.3386/W28920.
Acemoglu, D. og Johnson, S. (2023) Power and progress. London: John Murray.
Agrawal, A.K., Gans, J.S. og Goldfarb, A. (2023) ‘The Turing Transformation: Artificial Intelligence, Intelligence Augmentation,
and Skill Premiums’, National Bureau of Economic Research Working Paper Series, No. 31767. Tilgjengelig fra: https://doi.
org/10.3386/w31767.
Autor, D.H., Dorn, D. og Hanson, G.H. (2013) ‘The China Syndrome: Local Labor Market Effects of Import Competition in the United
States’, American Economic Review, 103(6), pp. 2121–2168. Tilgjengelig fra: https://doi.org/10.1257/aer.103.6.2121.
Autor, D., Caroline, C., Salomons, A.M. og Seegmiller, B. (2022) ‘New Frontiers: The Origins and Content of New Work, 1940–2018’,
National Bureau of Economic Research, Working Paper, Tilgjengelig fra: https://www.nber.org/papers/w30389.
Arbeidsmarkedet for helsepersonell fram mot 2040 (n.d.) [online]. Tilgjengelig fra: https://www.ssb.no/arbeid-og-lonn/sysselsetting/
artikler/arbeidsmarkedet-for-helsepersonell-fram-mot-2040 (hentet 16.november 2023).
Brynjolfsson, E., Li, D. og Raymond, L.R. (2023) ‘Generative AI at Work’, NBER Working Paper, No. 31161. Tilgjengelig fra: https://
doi.org/10.3386/w31161 (hentet 16. November 2023).
Dell’Acqua, F. m.fl. (2023) ‘Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on
Knowledge Worker Productivity and Quality’, SSRN Electronic Journal [Preprint]. Tilgjengelig fra: https://doi.org/10.2139/
ssrn.4573321 (hentet 16. November 2023).
Eloundou, T. m.fl. (2023) ‘GPTs Are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models’, arXiv
preprint. Tilgjengelig fra: arXiv:2303.10130.
Gizmodo’s owner replaced its Spanish language journalists with AI – The Verge (n.d.) [online]. Tilgjengelig fra: https://www.theverge.
com/2023/9/1/23856029/gizmodo-shuts-down-spanishlanguage-site-ai-translations (hentet 16. November 2023).
ISCO to SOC crosswalk (n.d.) [online]. Tilgjengelig fra: https://www.bls.gov/soc/ISCO_SOC_Crosswalk.xls. (hentet 16. November 2023).
Jia, Z., Kornstad, T., Stølen, N.M. og Hjemås, G. (2023) Arbeidsmarkedet for helsepersonell fram mot 2040. Tilgjengelig
fra: https://unit.no (hentet 16. November 2023).
Næringsstandard og næringskoder – SSB (n.d.) [online]. Tilgjengelig fra: https://www.ssb.no/virksomheter-foretak-og-regnskap/
naeringsstandard-og-naeringskoder (hentet 16. November 2023).
OECD (2023) OECD Employment Outlook 2023: Artificial Intelligence and the Labour Market. OECD Publishing, Paris. Tilgjengelig
fra: https://doi.org/10.1787/08785bba-en (hentet 16. November 2023).
O*NET Occupations og Tasks (n.d.) [online]. Tilgjengelig fra: https://www.onetcenter.org/dictionary/20.1/excel/task_statements.html
(hentet 16. November 2023).
Noy, S. and Zhang, W. (2023) ‘Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence’, Science,
381, pp. 187–192. Tilgjengelig fra: https://doi.org/10.1126/science.adh2586 (hentet 16. November 2023).
Rogers, E.M. (2003) Diffusion of Innovations (5th ed.). New York:Free Press.
Standard for næringsgruppering (SN) (n.d.) [online]. Tilgjengelig fra: https://www.ssb.no/klass/klassifikasjoner/6 (hentet 16. November
2023).
Teknologirådet (2018) Kunstig Intelligens – Muligheter, utfordringer og en plan for Norge. Tilgjengelig fra: https://teknologiradet.no/
publication/kunstig-intelligens-norge/.
Teknologirådet (2024) Generativ kunstig intelligens i Norge. Tilgjengelig fra: https://teknologiradet.no/publication/
generativ-kunstig-intelligens-i-norge/.
7.VEDLEGG
Under følger rubrikken som er benyttet som instruksjon for språkmodellen. Vi har brukt OpenAI sin metode som utgangspunkt, og kategoriene har derfor litt andre navn. I rubrikken tilsvarer E0, E1, E2 og E3 våre kategorier ME, GE, EE og ES.’
#E Exposure Taxonomy
Consider the most powerful OpenAI large language model (LLM) This model can complete many tasks
that can be formulated as having text input and text output where the context for the input can be captured in 2000 words. The model also cannot draw up-to-date facts (those from <1 year ago) unless they are captured in the input.
Assume you are a worker with an average level of expertise in your role trying to complete the given task. You have access to the LLM as well as any other existing software or computer hardware tools mentioned in the task. You also have access to any commonly available technical tools
accessible via a laptop (e.g. a microphone, speakers, etc.). You do not have access to any other physical tools or materials.
Please label the given task according to the taxonomy below. ## E0 – No exposure
Label tasks E0 if direct access to the LLM through aninterface like ChatGPT or the OpenAI playground cannot reduce the time it takes to complete this task with equivalent quality by half or more.
If a task requires a high degree of human interaction (for example, in person demonstrations) then it should be classified
as E0.
Label as E0 or E2 if the task requires real-time verbal correspondence or audio communication via radio or telephone, even if an LLM could assist by writing scripts. Very specialized and repetitive tasks are likely performed frequently by the worker, so the utility of the LLM may be limited to the initial learning phase of the job and should be labeled E0. Label as E0 if an LLM only contributes totime reduction the first time the task is done.
##E1- Direct exposure
Label tasks E1 if direct access to the LLM through an interface like ChatGPT or the OpenAI playground alone can reduce the time it takes to complete the task with equivalent quality by at least half. This includes tasks that can be reduced to: – Writing and transforming text and code
according to complex instructions, – Providing edits to existing text or code following specifications, – Writing code that can help perform a task that used to be done by hand, – Translating text between languages, – Summarizing medium-length documents,
- Providing feedback on documents, – Answering questions about a document, or – Generating questions a user might
want to ask about a document.
##E2- Exposure by LLM- powerd applications
Label tasks E2 if having access to the LLM alone may not reduce the time it takes to complete the task by at least half, but it is easy to imagine additional software that could be developed on top of the LLM that would reduce the time it takes to complete the task by half. This software may include capabilities such as: – Summarizing documentslonger than 2000 words and answering questions about those documents – Retrieving up-to-date facts from the Internet and using those facts in combination with the LLM capabilities – Searching over an organization’s existing
knowledge, data, or documents and retrieving information.
Examples of software built on top of the LLM that may help complete worker activities include: – Software built for a home goods company that quickly processes and summarizes their up-to-date internal data in customized ways to inform product or marketing decisions – Software
that is able to suggest live responses for customer service agents speaking to customers in their company’s customer service interface – Software built for legal purposes that can quickly aggregate and summarize all previous cases in a particular legal area and write legal research memos tailored to the law firm’s needs – Software specifically designed for teachers that allows them to input a grading rubric and upload the text files of all student essays and have the software output a letter grade for each essay – Software that retrieves up-to-date facts from the internet and uses the
capabilities of the LLM to output news summaries in different languages.
##E3- Exposure given image capabilities
Suppose you had access to both the LLM and a system that could view, caption, and create images. This system cannottake video media as inputs. This system cannot accurately retrieve very detailed information from image inputs, such as measurements of dimensions within an image. Label
tasks as E3 if there is a significant reduction in the time it takes to complete the task given access to a LLM and these image capabilities: – Reading text from PDFs, – Scanning images, or – Creating or editing digital images according to instructions.
##Annotation examples:
Occupation: Inspectors, Testers, Sorters, Samplers, and Weighers Task: Adjust, clean, or repair products or processing equipment to correct defects found during inspections. Label (E0/E1/E2/E3): E0 Explanation: The model does not have access to any kind of physicality, and more than half of the task (adjusting, cleaning and repairing equipment) described requires hands or other embodiment.
Occupation: Computer and Information Research Scientist Task: Apply theoretical expertise and innovation to create
or apply new technology, such as adapting principles for applying computers to new uses. Label (E0/E1/E2/E3): E1 Explanation: The model can learn theoretical expertise during training as part of its general knowledge base, and the principles to adapt can be captured in the text input to
the model.
Activity: Schedule dining reservations. Label (E0/E1/E2/E3): E2 Explanation: Automation technology already exists for this (e.g. Resy) and it’s unclear what an LLM offers on top of using that technology (no-diff). That said, you could build something that allows you to ask the LLM to make a reservation on Resy for you. (E3)
Activity: Negotiate purchases or contracts. Label (E0/E1/E2/E3): E2 Explanation: You could have each party transcribe
their point of view and then feed this to an LLM to resolve any disputes (E3). That said, many people would need to buy into using new technological tools to accomplish this (system).
Occupation: Allergists and Immunologists Task: Prescribe medication such as antihistamines, antibiotics, and nasal, oral, topical, or inhaled glucocorticosteroids. Label (E0/E1/E2/E3): E2 Explanation: The model can provide guesses for different diagnoses and write prescriptions and case
notes. However, it still requires a human in the loop using their judgment and knowledge to make the final decision.
Output list with items “index: {TaskID }label: {label} explanation: {5 word explanation (Without “LLM can” or
similar)}” separated by “;”